Công nghệ trí tuệ nhân tạo (AI) đã thay đổi cách thức mà các viện nghiên cứu và các ngành công nghiệp giải quyết một loạt các vấn đề phức tạp. Đặc biệt, Deep Learning (DL) với mạng nơ ron là một công cụ mạnh mẽ để trích xuất thông tin từ bộ dữ liệu lớn thông qua hoạt động phân loại, dự đoán và hồi quy. DL cũng có tiềm năng trong các hoạt động phân tích thiếu tính khách quan, giúp trả về kết quả tính toán lại chính xác hơn. Đào tạo các mạng lưới nơ ron sâu (deep neural networks) đòi hỏi lượng tính toán rất lớn, có thể mất vài tuần nếu chỉ được thực hiện trên một nút CPU hoặc GPU. Đây có thể là rào cản chính trong việc áp dụng DL vào thực tế.
.jpg)
Kỹ thuật giảm dần ngẫu nhiên (Stochastic gradient descent - SGD) là kỹ thuật tối ưu hóa thường được sử dụng nhất để đào tạo các mạng lưới nơ ron sâu. Quá trình đào tạo đòi hỏi một tập dữ liệu đào tạo lớn, các thông tin của mỗi mẫu mà mạng dùng để học hỏi đều được dán nhãn. Một bước của SGD sử dụng một tập hợp con ngẫu nhiên của bộ dữ liệu, được gọi là một lô nhỏ, để tính toán các đạo hàm riêng cho mỗi tham số điều chỉnh được trong mạng. Các đạo hàm riêng này, hoặc các biến thiên riêng, đo sự khác biệt giữa đầu ra của mạng và kết quả đúng được cung cấp bởi các nhãn. Mỗi mẫu trong tập hợp con ngẫu nhiên lại tạo ra các biến thiên riêng. Tất cả các biên thiên có được từ mỗi mẫu lại được tính trung bình với nhau và giá trị trung bình này được sử dụng để cập nhật các tham số mạng cho bước SGD tiếp theo. SGD thay đổi khi có các công cụ tối ưu hóa mới (phương thức được sử dụng để cập nhật mô hình cung cấp các biến thiên riêng).
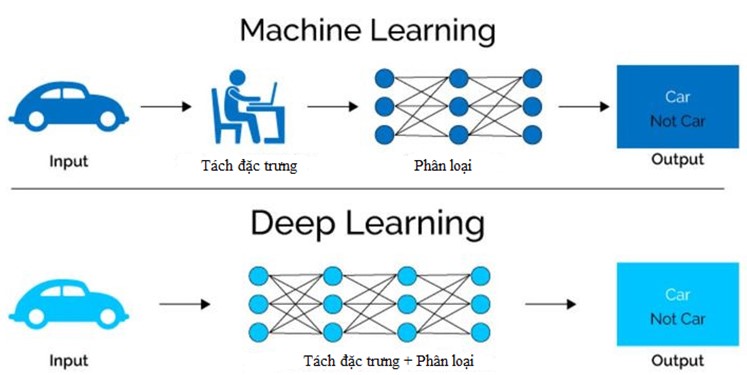
SGD có thể được song song hóa bằng cách chia đều một số lượng đủ lớn các lô nhỏ cho một tập các hoạt động xử lý. Mỗi hoạt động xử lý tính toán biến thiên cục bộ và sau đó gửi kết quả để tính toán biến thiên trung bình toàn thể. Các tham số mạng nơ ron (mô hình) sau đó được cập nhật với các biến thiên này. Kỹ thuật này được gọi là SGD song song dữ liệu đồng bộ(Synchronous data parallel SGD - SSGD).
Có thể giảm thời gian đào tạo DL sử dụng SSGD bằng cách tăng kích thước lô nhỏ toàn thể (trên tất cả các hoạt động xử lý) và tăng kích thước bước SGD, còn được gọi là tốc độ học tập (learning rate). Các lỗi trên các biến thiên trung bình toàn thể sẽ giảm khi nhiều mẫu hơn được sử dụng để tính toán. Lỗi giảm cho phép nhiều cập nhật hơn cho mô hình tại mỗi bước, từ đó dẫn đến sự hội tụ nhanh hơn. Có hạn chế đối với việc tăng kích thước lô nhỏ toàn cầu, đến một cỡ nào đó sẽ có hiện tượng hội tụ chậm hoặc không hội tụ. Khi đó cần sử dụng các công cụ tối ưu hóa tinh vi hơn để vượt qua những khó khăn trong đào tạo.
Trong khi nhiều khung DL có cung cấp chức năng cho đào tạo song song dữ liệu, thì hiệu suất khi sử dụng ở quy mô vài trăm nút trở lên là kém. Điều này chủ yếu là do cần chi phí tài nguyên lớn để giao tiếp giữa rất nhiều nút liên quan đến quá trình tính toán biến thiên trung bình toàn thể. Module cắm Cray PE DL Plugin giải quyết vấn đề này thông qua một kết hợp các cải tiến thuật toán độc đáo và tối ưu hóa cao hoạt động giao tiếp dựa trên Giao diện chuyển tin nhắn (Message Passing Interface – MPI). So với các khung DL tính toán các biến thiên trung bình toàn thể chỉ dựa trên một tính toán MPI chung Allreduce() thì Cray PE DL Plugin vượt trội hơn hẳn.
Ứng dụng DL trong cảnh báo, dự báo khí tượng thủy văn đang là một hướng nghiên cứu tiềm năng và có nhiều thách thức. Với lượng dữ liệu đầu vào lớn và yêu cầu dự đoán nhanh tức thời, tính chính xác cao, ứng dụng rất phù hợp xây dựng trên hệ thống Cray XC-40 sử dụng Cray PE DL Plugin.
Nguồn : https://www.cray.com/sites/default/files/resources/CUG-DeepLearning.pdf.
Biên dịch tin bài : Ngô Văn Mạnh - Đầu mối Ủy ban Hệ thống cơ sở CBS
Tổng hợp Vụ KHQT

.png)

.png)
.jpg)

.png)
.jpg)
.jpg)


.jpg)
.jpg)

